How I (Almost) Implemented a Production App in a Weekend
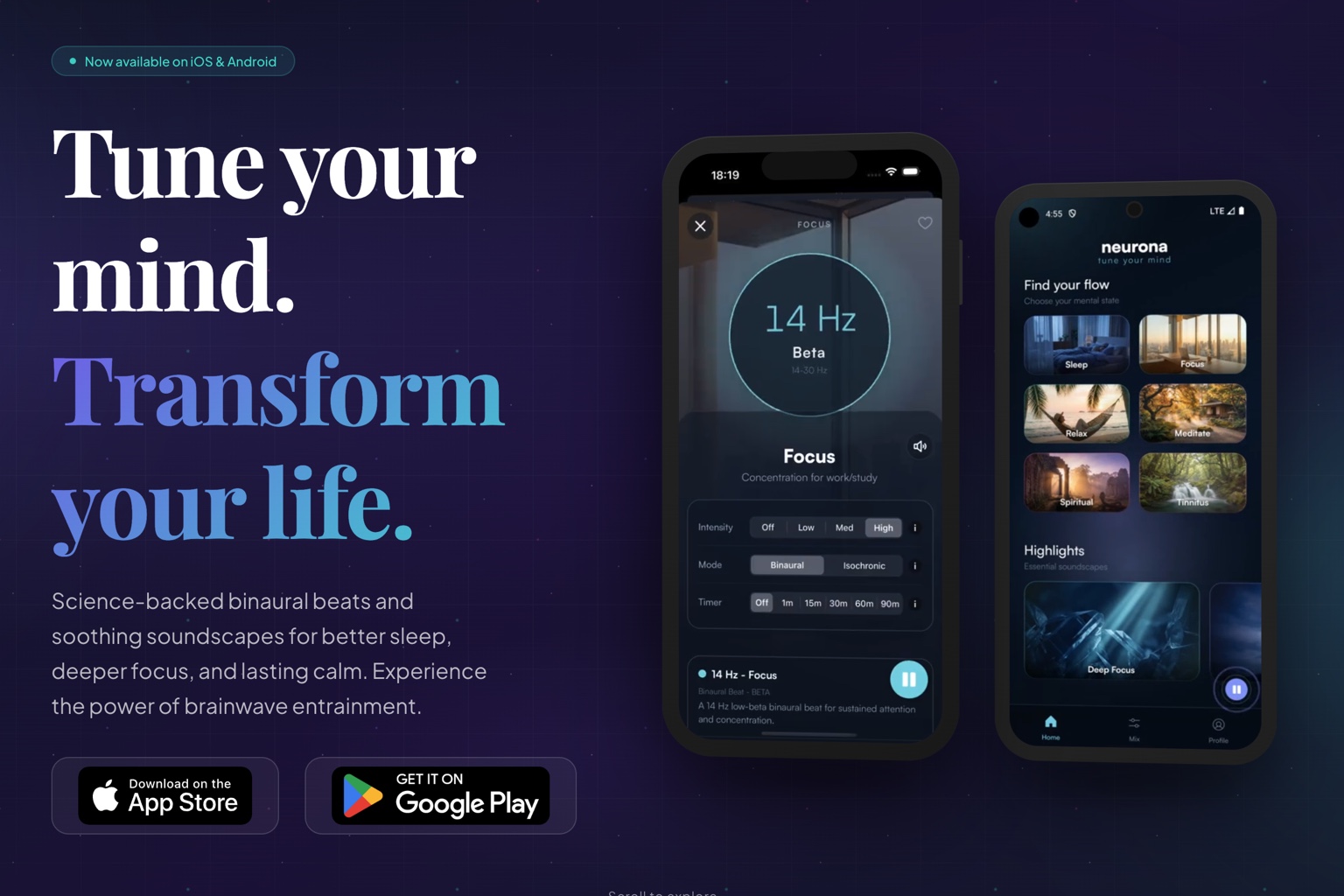
Shameless plug: if you want better focus and sleep, download Neurona first, then come back for the build story.
![]()
![]()
I wanted a simple weekend experiment, specifically to try the Ralph Wiggum technique from Geoffrey Huntley’s original article, Ralph Wiggum as a “software engineer”. Instead, I got a very honest lesson in modern AI development: getting a prototype is fast, shipping a real app is still work.
After Christmas, I started playing with autonomous coding agents and picked a project that looked perfect on paper: a binaural beats app. Real-time audio, subscriptions, polished UI, cross-platform support. What could possibly go wrong?
Short answer: enough to make the story interesting.
Weekend one: confidence, chaos, and silence
I started with native iOS (Swift + SwiftUI), because for audio apps that still feels like the “do it properly” choice.
I built a detailed plan with Claude, queued up a long autonomous run, then went out to watch a movie. Peak productivity theater.
When I came back, the app looked amazing:
- beautiful UI
- architecture everywhere
- hundreds of tests
Then I hit Play, and everything collapsed at once.
- no sound
- test runs crashing
- unstable behavior around async audio flows
The key issue was Swift 6 strict concurrency. Actor isolation and async boundaries in a complex multi-layer audio engine became a mess, and the generated code was too tangled to reason about safely.
I spent around two hours trying to fix it. I tried different prompts, different repair strategies, and different models. Same outcome: too much code, too many moving parts, not enough confidence.
At that point I gave up on that branch. Not because I love quitting, but because shipping requires good decisions, and “keep digging this hole” was a bad one.
Pivot: React Native + Expo, but first prove the audio
Instead of asking AI to build “the full app” again, I split the work:
- Build a tiny app with just buttons to test audio behavior.
- Only after that, build the complete product.
That tiny app was ugly and perfect. It played the right tones, mixed layers correctly, and gave me confidence that the core actually worked.
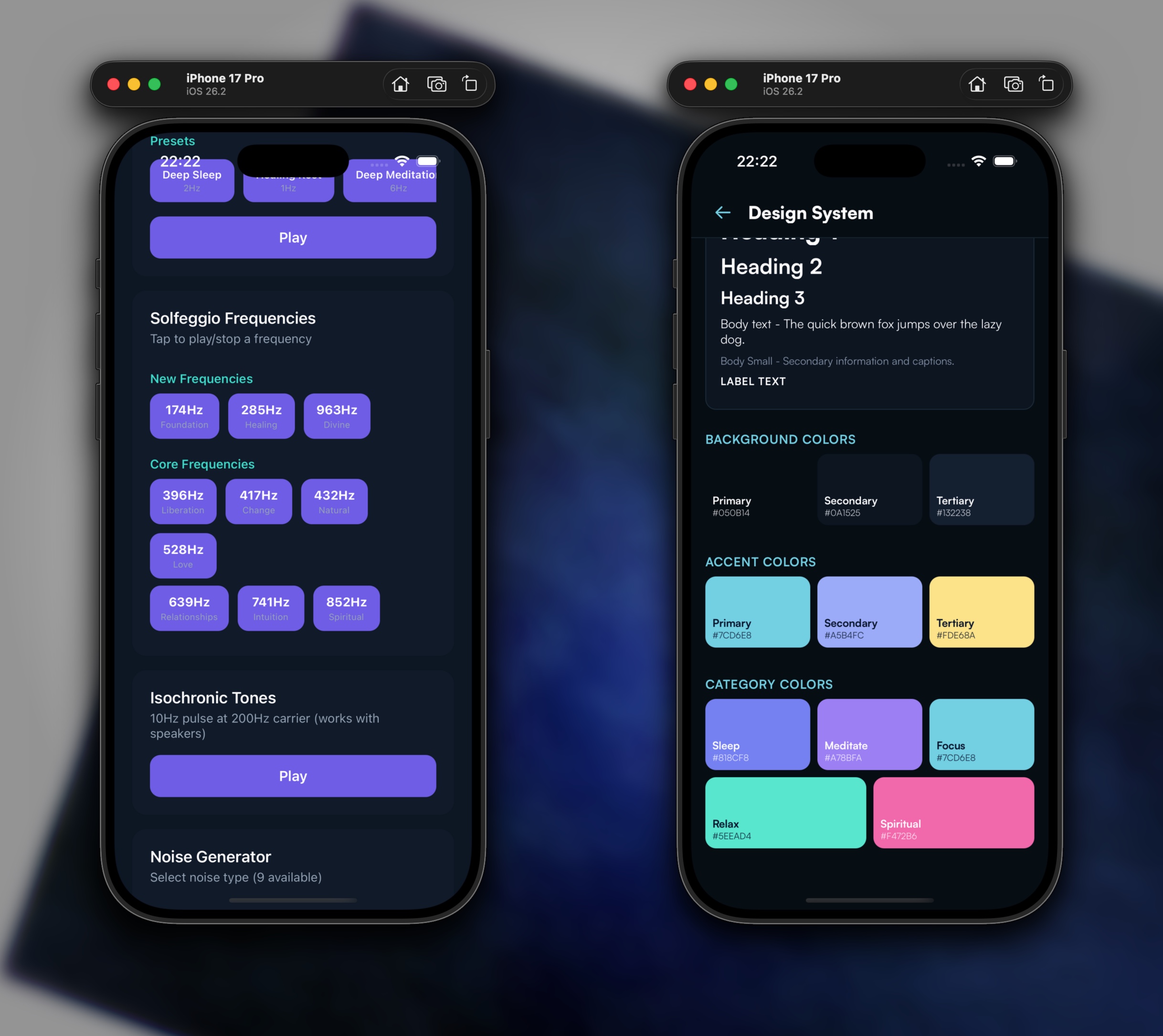
At the same time, we built the first version of the design system so the next iterations had consistent UI primitives instead of one-off screens.
This was a big lesson: when AI is involved, thin vertical slices beat big-bang implementation. Prove the risky part first, then scale.
Once that foundation was stable, the rest of the product moved fast and stayed stable.
The part people skip on social media
This is usually where someone posts: “Built and shipped in a weekend with AI.”
No.
I had a working prototype in a weekend. Shipping took around three weeks of evenings and weekends, and that phase is where Neurona became a real product.
The difference between prototype and production was not “write more code.” It was:
- remove regressions
- harden edge cases
- make subscriptions and restore flows reliable
- validate behavior screen by screen
- get platform-specific polish right
During that period I worked with multiple agents in parallel:
- Claude Code with Opus 4.5 for most implementation work
- Codex running gpt-5.2-codex when I needed stronger debugging loops
- Gemini 3 when I wanted cleaner UI iterations
I tested other models too, and honestly they were not good enough for this project. The model choice was the real differentiator: same prompts, very different outcomes.
Cross-platform done properly
The final app supports iOS and Android, and I also adapted the design language to support Liquid Glass for iOS 26 while keeping a solid retrofit path for iOS 18 and Android.
That sounds cosmetic until you try it. Platform polish is the difference between “it runs” and “it feels native.”
Same feature set, different platform expectations, different implementation details.
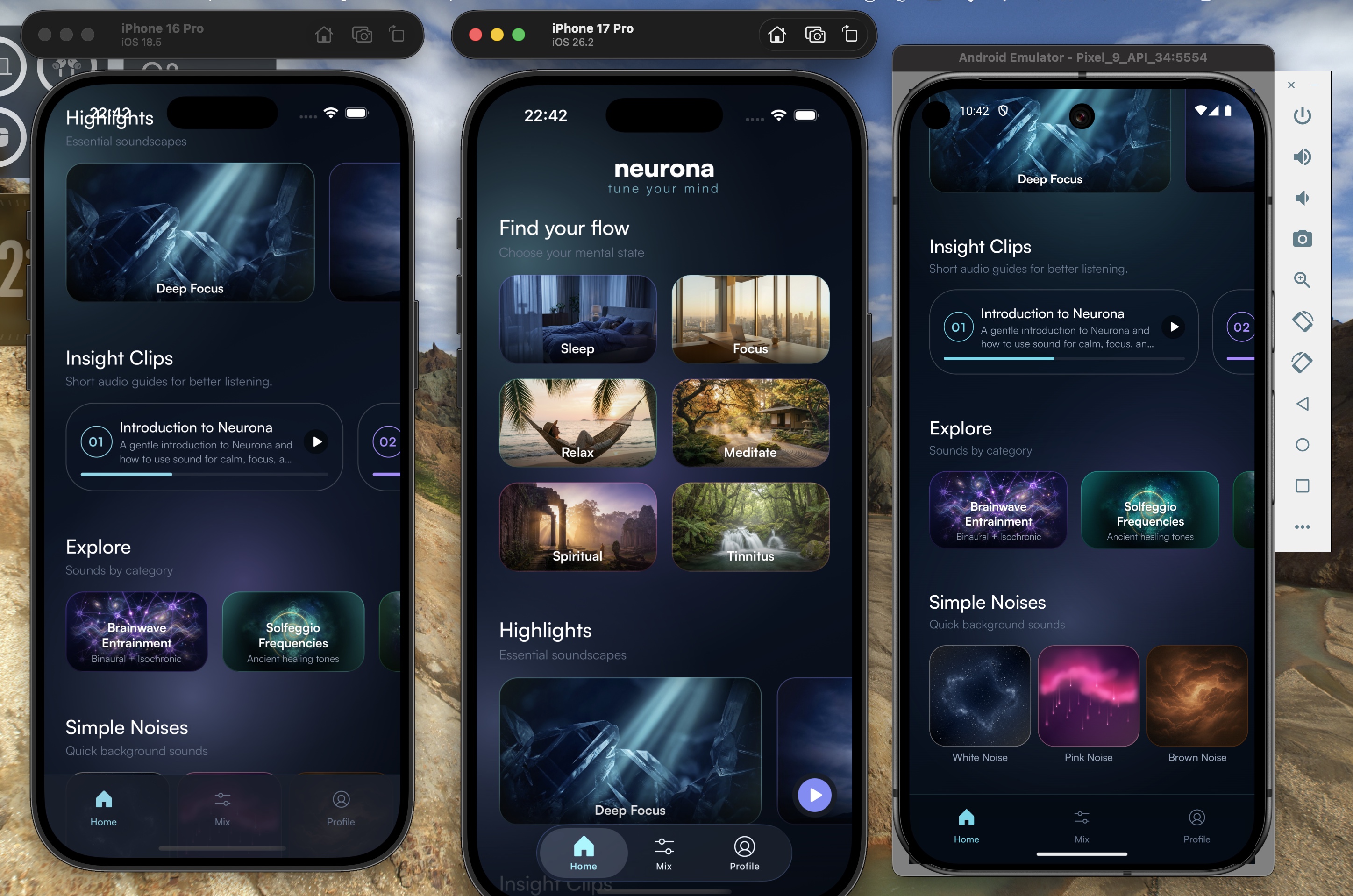
What actually shipped
By the end of the cycle, this was not just an app demo anymore:
- Neurona app for iOS and Android
- RevenueCat integration
- marketing website
- UI direction and visual assets produced with Nano Banana plus a custom skill I embedded in Claude Code
- podcast-style explainer pills with soothing music and an ASMR-like voice to explain the science behind binaural beats, implemented via Gemini Voice API
- screenshot pipeline for store assets
- release-ready flows, not just isolated features
The funniest part? I spent less time typing code and more time validating behavior, reviewing outputs, and deciding what “done” really meant.
Quality check: numbers, not vibes
For Neurona alone, the final result looked like this:
- 40,124 lines of TypeScript/TSX
- 64 React Native components
- 20 screens/routes
- 171 passing tests across 28 test suites
- 27 curated ambient sounds
And the weirdest part is still true: I never looked at the code. Not once.
My quality bar was simple and brutal:
- tests must pass
- features must behave exactly as expected
- no regressions from one screen to the next
That forced better specs, tighter validation, and fewer “looks good in the diff” mistakes.
I treated the app like a black box product, not a code craft project.
The screenshot grind (automated, thankfully)
App Store visuals can quietly eat days. I vibecoded a dedicated screenshot generation tool to produce the marketing shots in a repeatable way across devices and themes.
That tool paid for itself immediately.
What I actually learned (without the hype)
- Autonomous agents are great at getting you to a convincing first draft, not to a shippable product.
- Model quality is a hard constraint, not a minor preference. With weaker models, I got plausible output and fragile behavior. With Opus 4.5, gpt-5.2-codex, and Gemini 3, I got reliable progress.
- Swift 6 concurrency is unforgiving in complex audio systems. The native app failed exactly where concurrency discipline matters most, and trying to patch it late was expensive.
- Scope slicing is the best antidote to AI chaos. The “buttons-only audio test app” saved the project because it isolated the highest-risk technical assumption.
- “I never read the code” is viable only if your tests and acceptance criteria are strict. If your specs are vague, you lose. If your checks are sharp, this approach can be surprisingly effective.
- Shipping still takes judgment. AI can generate options, but deciding when to pivot, what to cut, and what quality bar to enforce is still the human job.
So no, I did not build a true production app in a weekend.
I almost did. Then reality showed up, and that was the useful part.